区间操作问题
- sparse-table算法
- 莫队算法
- 带修改莫队
- 高维莫队
- 树上莫队
- 一类阈值查询问题
- 多维平面操作问题
- 区间选择问题
- 区间颜色统计问题
- 区间最值算法
- 区间最近值问题
- 区间最大不相交集合
- 双区间操作问题
- 多维区间查询问题
- 区间k小问题
- 生长问题
- 参考资料
sparse-table算法
区间最值
st算法可以用于计算区间最值,不同于其它区间最值查询算法,st算法单次查询的时间复杂度仅为$O(1)$。下面讲解st算法。
假设区间的范围为$[0,n]$。我们首先定义函数$f(i,j)$表示区间$[i,i+2^j)$的最小值。很显然我们可以给出递推公式:
\[f(i,j)=min(f(i,j-1),f(i+2^{j-1},j-1))\]对于$i$,共有$0$到$n$总选择,而对于$j$,共有$0$到$\lfloor \log_2n \rfloor$种选择。总计对$f$的调用有$O(n\log2_n)$种可能,我们可以提前通过上面的递推公式以$O(n\log2_n)$的时空复杂度预处理得到。之后的所有$f$调用的时间复杂度都为$O(1)$,这也是st算法能够在$O(1)$时间复杂度内回答区间最小值的关键。
现在,假设我们要查询区间$[l,r]$的最小值。我们知道区间$[l,r]$的最小值,也就是$[l,r+1)$的最小值。记$k=\lfloor \log_2(r+1-l) \rfloor$,则$[l,r+1)$的最小值必定是$[l, l+2^k)$的最小值和$[r+1-2^k,r+1)$的最小值中的较小者,即$min(f(l,k), f(r+1-k,k))$。
上面的操作几乎可以认为是$O(1)$了,美中不足的是我们需要计算$\lfloor \log_2(r+1-l) \rfloor$。一般对于这种操作,各种语言都提供了接近$O(1)$的奇技淫巧,但是如果追求严格,可以以预先处理的方式以$O(n)$的时空复杂度计算$\lfloor \log_2x \rfloor$,其中$x=1,2,\ldots,n+1$。这样对数向下取整也能保证以$O(1)$的时间复杂度得到。
上面预处理的总的时间复杂度和空间复杂度均为$O(n\log_2n)$,而每次查询区间最值仅需要$O(1)$的时间复杂度。
LCA
LCA问题可以转换为区间最值问题,之后利用st算法就可以高效求解了。
首先我们对树进行深度优先搜索,当第一次访问结点$u$时,将$u.enter$记录为当前时间戳。之后比较特殊的是,在访问$u$时,我们首先将$u$加入某个列表尾部,之后每次访问$u$的子结点返回后,都要将$u$再次加入列表尾部,访问$u$完毕后将$u.leave$设置为当前时间戳。
第一次将$u$加入该列表尾部的费用由$u$支付,之后每次访问某个结点$v$后再次加入$u$的费用由边$(u,v)$支付,每次支付的费用为1,而一株大小为$n$的树中,结点数目为$n$,边的数目为$n-1$,因此最终搜索完毕后列表的大小为$2n-1$。
void dfs(root){
root.enter = list.size();
list.add(root);
for(Node child : root.children)
{
dfs(child);
list.add(root);
}
root.leave = list.size() - 1;
}
接下来,每次查询结点$x=lca(u,v)$,等价于查询list区间$I=[min(u.enter,v.enter), max(u.leave, v.leave)]$中$enter$值最小的哪个结点。这就是我们上面聊到的区间最值问题。
下面证明一下下面几点:
- 区间$I$中一定包含$u$与$v$的$x$。
- $x$是区间$I$中拥有最小$enter$值的结点。
如果$u=v$,落在区间$I$中的结点都是$u$的子结点,因此两条命题都是满足的。下面都认为$u.enter < v.enter$,由于$x=lca(u,v)$,那么可知$u$和$v$分别处在$x$下不同的两个子树中,因此在从含$u$的子树中递归返回后,$x$会被加入到列表尾部,之后会访问$v$,很显然命题1是满足的。并且在$x$返回之前,中间不会加入其它$x$的祖先结点,即$x$是拥有最小$enter$值节点,命题2是满足的。上面的推理对于$u=x$的情况也是一样的。
二维ST
ST可以直接推广到二维空间,记st[i][j][k][t]表示$x\in [i,i+2^j)$,$y\in [k,k+2^t)$的最值。因此对于大小为$n\times m$预处理的时间复杂度为$O(nm\log_2n\log_2m)$。查询实际上是查询4个矩形的并集,因此时间复杂度是$O(1)$。
提供一道题目。
莫队算法
莫队可以用于解决一类区间离线统计问题。如果我们以经统计了$[l,r]$的信息,现在要统计$[l+1,r]$、$[l-1,r]$、$[l,r-1]$、$[l,r+1]$(这四种转移是基础转移),如果你能很快滴给出答案,那么就可以用莫队来优化离线区间查询。
假设我们现在有一段长度为n的序列,之后有m个查询,每个查询需要统计一段区间的信息。
下面我们首先按固定大小k进行分块,若请求的左边界为l,那么它会落在块$\lfloor \frac{l}{k} \rfloor$中。首先对查询预先进行排序,排序的第一关键字为查询所属的块,第二关键字为查询的右边界r。
之后我们按顺序处理每个请求,只不过在切换请求时我们复用上一个请求留下来的区间统计信息。比如现在区间为$[a,b]$,而查询的区间为$[l,r]$,我们可以通过四种基础转移将区间进行转换,需要执行$|a-l|+|b-r|$次转移。
下面我们来分析时间复杂度:
对于块号相同的查询,由于查询的右边界递增,因此右边界最多移动n次。总共有n/k个块,故最多移动$n^2/k$次。
对于块号相同的查询,由于每次切换查询时,左边界最多移动k次,共有m个查询,因此最多移动$km$次。
对于不同块的交界,切换时,我们左边界和右边界可能需要重置,这部分最多需要$2n$次基础操作,块最多切换$n/k$次,因此总共移动$2n^2/k$。
加总所需的时间费用,总共为$O(m\log_2m+km+n^2/k)$,当我们取$k=n/\sqrt{m}$时,此时时间复杂度为$O(m\log_2m+n\sqrt{m})$。
带修改莫队
我们可以将莫队修改成支持单点修改的形式。
设区间长度为n,区间查询与单点修改共m次。如何用莫队优化。
我们为查询引入版本的概念,一个查询的版本为在该次查询发生之前发生的修改次数。之后我们选取一个数k,并进行分块。对于查询,其左边界为l,右边界为r,版本为v,其属于分块$(\lfloor \frac{l}{k} \rfloor, \lfloor \frac{v}{k} \rfloor)$。定义块号的顺序为块号的字典序。首先我们需要对查询进行预先排序,排序的第一关键字为查询所处块号,第二关键字为查询的右边界。
之后按顺序处理查询。对于一个查询,如果版本号为上一个处理的查询不同,我们还需要应用或回退一些修改。
下面证明时间复杂度:
对于同一个块的查询,右边界最多移动n次,块数不超过$nm/k^2$,因此右边界总计移动$n^2m/k^2$。
对于同一个块中的查询,左边界和版本号最多分别变动k次,因此总共最多发生$2mk$次变动。
对于块之间的切换,每次左边界最多修改n,右边界最多修改n,版本最多修改m,因此总共发生$(2n+m)nm/k^2$次修改。
总的时间复杂度为$O(m\log_2m+3n^2m/k^2+2mk+nm^2/k^2)$。当我们取k为$n^{2/3}$时,得到时间复杂度$O(m\log_2m+n^{2/3}m+m^2/n^{1/3})$。
高维莫队
考虑$[0,N]^k$向量空间,我们初始时位于$(0,\ldots,0)$处。现在有$Q$个目的地$p_1,\ldots,p_n$。我们需要经过所有目的地。每次我们可以移动到曼哈顿距离为$1$的另外一个整数点上。问最少需要的步骤数。
这个问题是旅行商问题,是NP问题。因此我们将问题改成,设计一条足够短的路径。
很显然我们直接从起点到$p_1$,从$p_1$到$p_2$,如此重复下去,就能得到一条路径,但是这条路径的长度可能达到$QkN$。
这里我们可以使用一个简单的优化,就是将$k$个维度的前$k-1$个维度进行分块,块大小为$B$。接下来我们对所有请求进行排序,首先按照所在块进行排序(同一块的请求放在一起),如果块相同则按照第$k$个维度进行排序。
对于每个请求块内的转移费用最多为$(k-1)B$,而对于每个块其第$k$个维度的转移所需步骤为最多为$N$。同时切换块的时候转移为$kN$。块的数目为$(\frac{N}{B})^{k-1}$。因此总的步骤上限为$Q(k-1)B+(\frac{N}{B})^{k-1}(N+kN)$。
上面如果我们取$B=N^\frac{k-1}{k}$,这样需要的步骤数为$O(QkN^{1-\frac{1}{k} }+(k+1)N^{2-\frac{1}{k} })=O(kN^{1-\frac{1}{k}}(Q+N))$。
这里一般认为$Q=O(N)$,这样需要的步骤数为$O(kN^{2-\frac{1}{k}})$。
下面我们用高维莫队来解释已有的莫队:
- 普通的序列上的莫队,请求由$l,r$两个属性决定,我们可以将其映射到二维空间上。现在我们从$0$出发,要处理所有请求(经过所有请求),莫队算法提供的步骤数为$O(2N^{1.5})$。这里每一步的费用为1,因此时间复杂度也是$O(2N^{1.5})$。
- 考虑在二维数组上,我们需要查询某个子矩阵中的各种信息。每个请求可以由$l,r,b,t$决定,可以映射到四维空间。因此用莫队解决所需步骤数为$O(4N^{1.75})$。当然你说这时间复杂度怎么可能,当然我们这里并没有提及时间复杂度,实际上二维数组上每移动一步的费用为$O(N)$(比如$l$增大,对应要删除最左边的列,共$O(N)$个元素),因此时间复杂度为$O(4N^{2.75})$,依旧比暴力的$O(N^3)$好。
- 考虑带修改莫队,每个请求都由$l,r,time$所决定,因此可以映射到三维空间。所以用莫队解决所需步骤数为$O(3N^{1.667})$。但是和二维数组上的莫队不同,这里每步的费用也是$O(1)$,因此时间复杂度为$O(3N^{1.667})$。
树上莫队
莫队可以扩展到树上。
对于子树查询,我们可以先计算树的dfs序,之后子树的dfs序一定是连续的,形成一个区间。那么实际上如果我们将结点按照dfs序铺平,那么子树查询就对应了普通的区间查询,直接可以上莫队。同样在这种情形下要支持单点修改,将普通莫队替换为带修改莫队即可。
还有一类比较神奇的应用是树上路径统计。我们知道一株树可以用括号序列来表示,比如(()())是一个根结点带两个叶结点。一个结点在其括号序列中对应两个括号,一个开括号一个闭括号。那么要查询从u到v的路径,我们这边假设u的左括号在v的左括号之前出现,那么可以发现在括号序列中,u的右括号到v的左括号之间仅u到v的路径上顶点的括号正好出现一次,其余顶点的括号要么成对出现要么不出现。因此我们可以认为一个顶点出现奇数次则包含入结果,否则从结果剔除。这里需要特别注意的是u和v的lca可能需要手动处理。
一类阈值查询问题
所谓的阈值问题是指要让你维护一个数组,支持区间更新,以及查询某个区间中有多少数大于等于$k$。
问题1:给定一个序列$a_1,a_2,\ldots, a_n$和一个数$k$,给定m次操作,操作分成两种,第一种是将区间中所有元素加上某个数$x$,第二种操作是询问区间中所有大于等于$k$的元素值的和,这个问题中$x\geq 0$,$n,m\leq 10^5$
由于$x\geq 0$,我们可以直接暴力维护两颗线段树,第一颗线段树维护数组中所有小于$k$的元素的信息,第二颗线段树维护所有大于等于$k$的元素信息。每次更新操作都需要同时修改两颗线段树,并且修改完后需要不断检查第一颗线段树中最大的元素是否大于等于$k$,如果是,将其从第一颗线段树中删除,并迁移到第二颗线段树中。查询只需要查询第二颗线段树。由于每个区间中的元素最多会被迁移一次,因此时间复杂度为$O((n+m)\log_2n)$。
问题2:给定一个序列$a_1,a_2,\ldots, a_n$和一个数$k$,给定m次操作,操作分成两种,第一种是将区间中所有元素加上$x$,第二种操作是询问区间中所有大于等于$k$的元素值的和,这个问题中$|x|=1$,$n,m\leq 10^5$。
这个问题的难点在于存在负数的情况,假如使用问题1中提到的算法那么就无法保证迁移只发生$n$次。
下面来聊聊做法,我们将区间分块维护,每一块的大小为$b=\sqrt{n}$。这样每次区间更新操作可以看成$b$个块的完全更新和$2$个块的局部更新。前者我们用惰性标记,同时计算一下有哪些数大于等于$k$。后者我们可以直接暴力更新即可。这里值域比较大,我们可以用哈希表来存储每个块中元素值为$t$的所有元素的总和。查询操作就加总一下所有块即可,总的时间复杂度为$O(n\sqrt{n})$,这里由于使用了哈希表所以可能常数比较大。
问题3:给定一个序列$a_1,a_2,\ldots,a_n$。之后$m$次操作,操作分为三类:
- 给定区间$l_i,r_i,x_i$,对于$l_i<j<r_i$,将$a_j$修改为$\max(a_j,x_i)$
- 查询区间$l_i,r_i,x_i$,输出$\sum_{j=l}^r\max(a_j-x_i,0)$
这里保证第二类请求中$x_i$非严格递增,$1\leq n,m\leq 10^6$
我们可以用Segment tree beats来解决这个问题,对于第一类更新操作,Segment tree beats本来就支持。考虑第二类操作,我们可以这样做,将所有数都增大到至少$x_i$,这样区间和就是原本的区间和减去$(r-l+1)\cdot x_i$,注意到由于第二类请求的$x_i$递增,因此增大操作不会影响后面请求的结果。
问题4:给定一个序列$a_1,a_2,\ldots,a_n$。之后$m$次操作,操作分为三类:
- 给定区间$l_i,r_i,x_i$,对于$l_i<j<r_i$,将$a_j$修改为$\max(a_j,x_i)$
- 查询区间$l_i,r_i,x_i$,输出$\sum_{j=l}^r\max(a_j-x_i,0)$
这里保证第二类请求中$x_i$非严格递减,$1\leq n,m\leq 10^6$
这道题可以这样做。我们可以建立两个线段树,第一个线段树维护序列中$a_j<x_i$的部分,而第二个线段树维护其余部分。可以发现我们在整个过程中不断将元素从第一个线段树中移动到第二颗线段树中。可以证明移动的元素总数不会超过$O(n)$。第二类线段树由于需要支持总和和区间取最大操作,因此需要用Segment tree beats来实现。
而总和的话只需要去第二颗线段树中查询即可。时间复杂度为$O((n+m)\log_2n)$。
提供一道题目。
问题5:给定一个序列$a_1,\ldots,a_n$,之后$m$次查询,每次查询给定三个数$l_i,r_i,x_i$,要求计算$\sum_{i=l_i}^{r_i} \max(a_i,x_i)$。其中$1\leq n,m \leq 10^6$
一般阈值查询问题都是需要用到分块的,但是可以发现这个问题中没有修改,因此我们可以任意决定请求的顺序。我们可以将请求按照它们的$x_i$递减排序+BIT来解决,时间复杂度为$O((n+m)\log_2n)$。
多维平面操作问题
一般的区间操作都是发生在一维平面上的,但是当这些区间操作发生在多维平面上时,问题将变得非常困难,甚至不能给出多项式时间内的解法。
问题1:给定一个$n\cdot m$的矩阵$1\leq n,m\leq 10^9$,每个矩阵单元的初始值都是0。之后给出$q$次请求,每次请求要么要求你将落在某个子矩形中的所有单元都加上一个数(可能是负数),要么要求查询某个子矩形中所有单元的值的和
这个问题可以直接用稀疏二维线段树解决(动态开点)。但是这样的空间复杂度为$O(q\log_2n\log_2m)$。
问题2:给定一个$n\cdot m$的矩阵$1\leq n,m\leq 10^9$,每个矩阵单元的初始值都是0。之后给出$q$次请求,每次请求要么要求你修改某个单元的数(可能是负数),要么要求查询某个子矩形中所有单元的值的和
这个问题可用问题1的方案直接解决。如果我们将每次更新看成点的增加和删除,将请求发生的时间作为第三个维度,那么我们可以将查询操作视作在三维平面上的某个立方体中的顶点权值总和的查询,这允许我们用CDQ分治疗解决,时间复杂度为$O(q(\log_2q)^2)$,空间复杂度为$O(q)$。
问题3:给定一个$n\cdot m$的矩阵,$1\leq n,m\leq 10^9$,之后给出$q$个请求,每次请求要么要求你修改某个单元的数(可能是负数),要么要求查询某个子矩形中所有单元的值的最大值
这个问题可以直接用稀疏二维线段树解决。时间复杂度和空间复杂度均为$O(q\log_2n\log_2m)$。
问题4:给定一个$n\cdot m$的矩阵,$1\leq n,m\leq 10^3$,之后给出$q$个请求,每次请求要么要求你将落在某个子矩形中的所有单元都加上一个数(可能是负数),要么要求查询某个子矩形中所有单元的值的最大值
这个问题可以用这种方式解决,我们可以建立Quad tree,之后你就可以以$O(n+m)$时间复杂度处理每个请求,总的时间复杂度为$O((n+m)q)$。
问题5:给定一个$n\cdot m$的矩阵,$1\leq n,m\leq 10^9$,,每个单元的初始值都是0。之后给出$q$个请求,每次请求要么要求你将落在某个子矩形中的所有单元都加上一个数(可能是负数),要么要求查询某个子矩形中所有单元的值的最大值,这里$q\leq 10^4$。
我们没法开quad tree,因为矩阵太大了。这里我们可以对请求进行离散化操作,将一个矩形拆分成$12$个点。如下图。
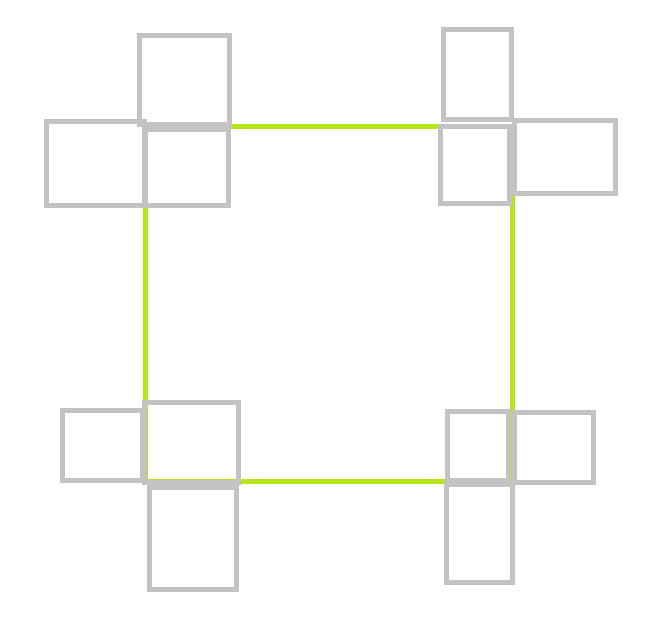
之后可以用KD树求解,由于$k$维KD树区间查询修改的时间复杂度是$O(n^{1-\frac{1}{k}})$,而这里维度是2,因此时间复杂度为$O(q\sqrt{12q})$
区间选择问题
问题1:给定一个序列$a_1,a_2,\ldots, a_n$,以及$m$个区间$I_1=[l_1,r_1],I_2=[l_2,r_2],\ldots, I_m=[l_m,r_m]$。现在我们允许选择任意个区间,将所有被至少一个选中区间覆盖的元素$a_i$加总,问总和最大可以为多少。其中$-10^9\leq a_i \leq 10^9,1\leq n\leq 10^5,1\leq m\leq 10^5$。
可以发现,如果我们选择了两个区间$[l_i, r_i]$和$[l_j,r_j]$,且$l_j\leq l_i \leq r_i\leq r_j$,那么区间$i$是否选择并不会影响结果。因此我们可以认为不允许同时选择嵌套的区间。
对于区间$I_i$,我们为其建立一个DP状态$dp(I_i)$,其意义为已选的右边界最大的区间为$[l_i,r_i]$的前提下最大总和是多少。
第一类转移:对于区间$j$,如果$r_j<l_i$,那么转移公式为:$dp(I_i)=dp(I_j)+s(r_i)-s(l_i-1)$,其中$s(k)=a_1+\ldots+a_k$。
第二类转移:对于区间$j$,如果$l_j\leq l_i \leq r_j\leq r_i$,这时候两个区间有交,此时转移公式为:$dp(I_i)=dp(I_j)+s(r_i)-s(r_j)$。
有了转移公式,那么如果找到这些满足条件的$j$呢。我们可以将区间的左边界作为横坐标,将区间的右边界作为纵坐标,这时候会发现所有两类转移都落在由$(0,0)$和$(l_i,r_i)$组成的矩形内。且矩形中坐标大于等于$l_i$的为第二类转移,小于$l_i$的为第一类转移。
上面的几何化意味着我们可以用二维线段树来维护平面信息,但是实际上我们可以通过提前对一个维度进行排序处理的技术,使用普通线段树就可以维护了。
对于第一类转移和第二类转移需要分别建立一颗线段树进行维护。总的时间复杂度为$O(n+m(\log_2n+\log_2m))$。
提供一道Atcoder的题目。
问题2:给定一个序列$a_1,a_2,\ldots, a_n$,以及$m$个区间$I_1=[l_1,r_1],I_2=[l_2,r_2],\ldots, I_m=[l_m,r_m]$。现在我们恰好选择$k$个区间,将所有被至少一个选中区间覆盖的元素$a_i$加总,问总和最大可以为多少。其中$-10^9\leq a_i \leq 10^9,1\leq n\leq 10^5,1\leq m\leq 10^5$。
首先在不考虑$k$的约束情况下,这个问题与问题1无异。可以发现随着$k$增大,增幅会越小,这意味着由$k$和最优解组成的曲线是一个上凸包。考虑到这些,我们就可以利用WQS技术结合问题1求DP的方式解决这个问题,时间复杂度为$O((n+m(\log_2n+\log_2m))\log_2M)$,其中$M$与数值大小以及精度有关,一般不会超过$60$。
问题3:给定一个序列$a_1,a_2,\ldots, a_n$,以及$m$个区间$I_1=[l_1,r_1],I_2=[l_2,r_2],\ldots, I_m=[l_m,r_m]$。现在我们任意选择区间,将所有被至少一个选中区间覆盖的元素$a_i$加总,问总和最大可以为多少。其中$0\leq a_i \leq 10^9,1\leq n\leq 10^6,1\leq m\leq 10^6$。
这道题连题都不算,我们直接将所有被至少一个区间覆盖的数值加总起来即可,时间复杂度$O((n+m)\log_2n)$,如果区间已经被按照左边界排序过,那么时间复杂度为$O(m+n)$
问题4:给定一个序列$a_1,a_2,\ldots, a_n$,以及$m$个区间$I_1=[l_1,r_1],I_2=[l_2,r_2],\ldots, I_m=[l_m,r_m]$。现在我们要正好选择$k$个区间,将所有被至少一个选中区间覆盖的元素$a_i$加总,问总和最大可以为多少。其中$0\leq a_i \leq 10^9,1\leq n\leq 10^6,1\leq m\leq 10^6$。
这道题实际上是问题2的简化版,于是我们直接可以得出一个$O((n+m(\log_2n+\log_2m))\log_2M)$的做法。但是这道题的数据范围加大了,因此这种做法会超时。
可以想到用WQS二分来解决这个问题,但是现在问题来了,如何计算每次决策惩罚$C(C\geq 0)$的情况下最优能得到的总权。
首先我们还是假设不能选择两个相互包含的区间,因为这是没有意义的。
对于区间$I_i$,我们为其建立一个DP状态$dp(I_i)$,其意义为已选的右边界最大的区间为$[l_i,r_i]$的前提下最大总和是多少。
第一类转移:对于区间$j$,如果$r_j<l_i$,那么转移公式为:$dp(I_i)=dp(I_j)+s(r_i)-s(l_i-1)$,其中$s(k)=a_1+\ldots+a_k$。
第二类转移:对于区间$j$,如果$l_j\leq l_i \leq r_j\leq r_i$,这时候两个区间有交,此时转移公式为:$dp(I_i)=dp(I_j)+s(r_i)-s(r_j)$。
对于第一类转移,由于$s(r_i)-s(l_i-1)$是常数,因此我们只需要取最大的$dp(I_j)$即可。而对于第二类转移,比较复杂,但是注意到$s(i)$是非严格递增函数,因此我们可以使用斜率优化计算。
因此在已知惩罚的前提下,一次DP的时间复杂度为$O(n+m)$,结合WQS二分总的时间复杂度为$O((n+m)\log_2M)$,是可以通过的。
提供一道CF题目。
问题5:给定一颗树,树根为1,树上有$n$个顶点,第$i$个顶点有一笔价值$w_i$的财富。其中$m$个顶点是特殊的,我们现在可以派出$k$个人,从$k$个特殊的顶点出发,向根出发,搜集路上所有的财富(同一个顶点的财富只会被搜集一次)。问我们最多可以得到多少总财富?其中$0\leq w_i \leq 10^9,1\leq k\leq n\leq 1000$
这个题目首先可以想到费用流,我们将每个顶点拆分成两个,两个顶点连一条费用为$-w_i$容量为1的边。每个顶点同时连源点和汇点。看最优值即可。总的时间复杂度为$O(kV\log_2V)$,这里使用Dijkstra优化的费用流。
问题6:给定一颗树,树根为1,树上有$n$个顶点,第$i$个顶点有一笔价值$w_i$的财富。我们现在可以派出$k$个人,从$k$个顶点出发,向根出发,搜集路上所有的财富(同一个顶点的财富只会被搜集一次)。问我们最多可以得到多少总财富?其中$-10^9\leq w_i \leq 10^9,1\leq k\leq n\leq 10^6$
我们可以直接用贪心法证明,每次选择出发收益最大的顶点出发,$k$次后得到的就是最大收益。假设$v$是初始时出发收益最大的顶点,那么如果最后的方案中不选择$v$,记方案中被搜集的顶点形成的树为$T$,我们可以找到$T$中$v$的深度最小的祖先,回退之前$T$下的任意一个特殊顶点带来的影响,并加入$v$,可以证明这时候我们的收益是不会减少的。
首先我们可以利用所有顶点的dfs序构建线段树,之后利用线段树实现区间修改和弹出全局收益最大顶点的能力(即大根堆)。
第一次增广非常容易,找到收益最大的顶点$v$即可。将其弹出后,我们暴力枚举其所有祖先,之后修改祖先下其余顶点的收益,比如枚举到祖先$a$,祖先到当前顶点的路径中除了祖先外,深度最小的顶点记作$b$,那么我们将$a$代表的子树中的所有顶点的权重减去$a$的收益,但是$b$中的子树需要另外加上$a$的收益(即抵消该次变化)。而对于$v$,我们将$v$下所有顶点减去$v$的收益。这样我们遍历$v$的所有未被处理过的祖先就可以修正剩余所有特殊顶点的收益了。
可以发现每个每个顶点最多被访问一次,因此总的时间复杂度为$(n+k)\log_2n$。
给一道BZOJ题目,是这道题的弱化版。
区间颜色统计问题
题目1:给定一个序列$a_1,\ldots,a_n$,之后给出$q$个查询,第$i$个查询为$l_i,r_i$,询问$a_{l_i},\ldots,a_{r_i}$中有多少不同的数。
典型问题,最简单的方式就是直接用莫队,时间复杂度为$O(n\sqrt{n})$。但是实际上这个问题存在$O(n\log_2n)$的解法。
首先定义一个新序列$b_1,\ldots,b_n$,$b_i$表示第$i$个数之前与$a_i$相同的数中最大的下标(如果不存在则设为$-1$)。那么现在查询询问的实际上是区间$b_{l_i},\ldots,b_{r_i}$中有多少数小于$l_i$。
实际上我们可以把第$i$个数转换成二维平面点:$(i,b_i)$。这样查询其实询问的是某个二维平面中子矩形中的顶点数目。由于是离线查询,因此可以用线段树$O(n\log_2n)$求解。
题目2:给定一个序列$a_1,\ldots,a_n$,之后给出$q$个查询,第$i$个查询为$l_i,r_i$,询问$a_{l_i},\ldots,a_{r_i}$中有多少不同的数。查询强制在线。
由于是在线查询,因此莫队方法是行不通的。
我们可以用题目1的技巧将问题转换为二维点,之后用持久化线段树替换普通线段树,这样就可以支持在线查询了,时间复杂度和空间复杂度均为$O(n\log_2n)$。
题目3:给定一个序列$a_1,\ldots,a_n$,之后给出$q$个操作,操作分为两类:第一类,查询$l_i,r_i$,询问$a_{l_i},\ldots,a_{r_i}$中有多少不同的数;第二类,修改某个$a_{x_i}$,将其修改为某个指定数。
由于可以离线,所以用带修莫队可以过,时间复杂度为$O(n^{\frac{5}{3}})$。
同样我们将每个值转换为二维点,而修改操作就变成了增加点和删除点(对应点权为$1$和$-1$)。因此第$i$个值转换为$(i,b_i,t_i)$,其中$t_i$表示这个顶点出现的时间。之后问题就变成了三维空间的子矩形问题,可以利用CDQ分治以$O(n(\log_2n)^2)$的时间复杂度求解。
题目4:给定一个序列$a_1,\ldots,a_n$,之后给出$q$个操作,操作分为两类:第一类,查询$l_i,r_i$,询问$a_{l_i},\ldots,a_{r_i}$中有多少不同的数;第二类,修改某个$a_{x_i}$,将其修改为某个指定数。要求查询和修改在线。
莫队继续躺好。
将每个值转换为二维点之后,问题就变成了在线删点、加点以及统计区间,稀疏二维线段树足矣。时间复杂度和空间复杂度均为$O(n(\log_2n)^2)$。
题目5:给定一株拥有$n$个顶点的树,第$i$个顶点上写着$a_i$。要求统计每个顶点作为根的子树下有多少不同的数。
树上DSU可以轻松解决,时间复杂度为$O(n\log_2n)$。
题目6:给定一株拥有$n$个顶点的树,第$i$个顶点上写着$a_i$。之后$q$个查询,每个查询指定两个顶点$u,v$,要求回答$u$到$v$的唯一路径上的顶点上总共写着多少不同的数字。
树上路径统计是莫队的强项,直接用树上莫队即可。时间复杂度为$O(n\sqrt{n})$。
题目7:给定一株拥有$n$个顶点的树,第$i$个顶点上写着$a_i$。之后$q$个操作:操作1,指定两个顶点$u,v$,要求回答$u$到$v$的唯一路径上的顶点上总共写着多少不同的数字;操作2,修改某个顶点上的数字。
树上带修莫队,时间复杂度为$O(n^{\frac{5}{3}})$。
题目8:给定$k$和$n$个整数组成的序列$a_1,\ldots,a_n$,且$1\leq a_i\leq k$,记$f(a)$表示$a$存在多少个包含所有$1$到$k$之间的整数的子串。之后要求处理$m$个请求,每个请求要么要求输出$f(a)$,要么要求将某个$a_i$改为$0$。其中$1\leq n,m,k\leq 10^6$。
我们可以记$R(i)$表示最小的下标,满足$i\leq R(i)$,且$a_i,\ldots,a_{R(i)}$包含$1$到$k$中的所有整数,很显然$R$是个递增函数。因此$f(a)=\sum_{1\leq i\leq n}n-R(i)+1$。
之后考虑第二类请求,将$a_i$设置为$0$。我们记$l$为$a_i$这个整数在$i$前面出现的最靠近$i$的位置,$r$为$a_i$这个整数在$i$后面出现的最靠近$i$的位置,因此$l\lt i\lt r$,且$a_l=a_i=a_r$。
考虑删除$a_i$的带来的影响。这时候仅$R(l+1),R(l+2),\ldots,R(i)$可能会改变,其中对于$l+1\leq j\leq i$,$R(i)=chmax(R(i),r)$。
我们需要一种数据结构,可以支持区间设置上界,以及统计总和。这实际上已经有现存的数据结构了,叫做Segment tree Beat,它的每个操作的时间复杂度都是$O(\log_2n)$。
当然如果你不会Segment tree beat也不要紧。因为$R$是递增函数,因此我们可以找到最小的下标$t$,满足$l+1\leq t\leq i$且$R(t)>r$,$R(t-1)\leq r$,之后就是线段树的区间赋值操作而已。这里找$t$可以通过在线段树上完成二分,时间复杂度均为$O(\log_2n)$。
总的时间复杂度为$O(n+m\log_2n)$。
题目9:给定一个$n\times m$的二维网格,其上有$k$个位置被着色。要求计算有多少个不同的子矩形,矩形覆盖的网格包含了所有在二维网格出现的所有颜色。其中$1\leq n,m\leq 10^9$,$k\leq 2\times 10^3$。结果对$p$取模。
题目来源。
这道题目我们可以通过枚举左下角顶点,统计有多少个不同的右上角顶点,来计算结果。
如果我们固定子矩形的上下边界,那么我们可以$O(k)$计算有多少这样的子矩形。但是这样要求我们枚举所有的上下边界,时间复杂度为$O(k^3)$,太慢了。
现在考虑我们固定子矩形的下边界,为每个$x$位置维护$R(x)$,即最小的下标,满足以$x$作为左边界时候$R(x)$可以作为矩形的右边界。考虑这时候增大上边界的时候$R$的变化,此时我们需要额外加入一些点,因此$R(i)$可能减少。但是这样做总的时间复杂度还是$O(k^3)$,太慢了。但是如果我们一开始将上边界设为最大,并减少上边界,这时候相当于删除点,此时问题与题目8是类似的。我们可以$O(k\log_2k)$完成整个过程。而下边界只有$O(k)$种可能,因此总的时间复杂度为$O(k^2\log_2k)$。
题目10:给定一颗大小为$n$的树,以顶点$1$作为根。每个结点上都写了一个数字。接下来考虑处理$q$个请求,请求分两类:
- 将结点$u$的数字修改为$x$
- 查询$u$的子树中有多少不同的数字
其中$1\leq n, q\leq 5\times 10^5$
提供一道题目。
用dfs序来维护结点之间的顺序,问题实际是单点修改加区间颜色统计,我们可以用三维偏序来解决这个问题,时间复杂度为$O((n+m)(\log_2(n+m))^2)$。
实际上这个问题和之前提到的问题略有区别,因为这个问题的查询区间仅可能是子树,因此我们可以把时间复杂度优化到$O((n+m)\log_2n)$。
具体的思路就是我们考虑单个颜色的状态贡献。记单个颜色出现的结点的的dfs序分别为$a_1,\ldots,a_k$。那么我们可以考虑让所有结点的权值都增加1,之后将$lca(a_i,a_{i+1})$的权值减少$1$。可以发现这时候所有结点,如果它的子树中存在这个颜色,那么它的子树和中所有这种颜色的结点的总贡献正好为$1$(实际上我们可以从虚树的角度来理解,由于每个结点的子树和为1,因此两个结点合并到同一个lca的时候,lca权值会减少1,因此lca的子树总和正好是1)。
这样一来我们考虑修改一个结点的颜色会发生什么,这等价于我们向上面序列$a$中间插入一个元素或删除一个元素,这个可以通过维护一个平衡树来快速查找前驱后继,并快速重新计算lca和贡献。时间复杂度优化到了$O((n+m)\log_2n)$。
区间最值算法
给定长度为$n$的序列,之后回答$q$个请求,每个请求要求查询区间最值。
区间最值分成带修改和不带修改两种,通过实现那些$O(n)$构建,$O(1)$查询的数据结构,很容易优化到$O(n+q)$。
接着考虑到带$m$次修改的区间查询算法。如果修改操作和查询操作会交错执行,那么需要使用线段树,时间复杂度为$O((m+q)\log_2n+n)$。
如果所有修改都发生在查询前,那么可以先将修改排个序,之后按序执行。这时候每个修改都在不影响之前修改的前提下,修改某个区间。我们可以维护一个并查集,来快速跳过那些已经被修改过的部分。这样时间复杂度为$O(m\log_2m+n+q)$。
区间最近值问题
题目1:给定$a_1,\ldots,a_n$,现在要求回答$m$个请求,第$i$个请求为$l_i,r_i$,要求在$l_i,\ldots,r_i$中找出两个不同的数$x,y$,要求$|a_x-a_y|$最小,要求输出$|a_x-a_y|$。其中$2\leq n\leq 10^5$, $1\leq m\leq 10^6$,且满足$l_i<r_i$,以及$0\leq a_i\leq 10^9=M$。
提供一道题目。
一开始认为是用莫队来做,但是这样做的时间复杂度是$O(n\sqrt{m}\log_2n)$,会超时。
我们可以离线处理请求。从大到小扫描$1$到$n$的下标,记做$i$。首先我们维护一个线段树,其中线段树的第$j$个元素表示区间$[j,i]$的答案(最接近的两个数的差值)。考虑下标$i-1$移动到$i$。这时候发生的变化。这时候出现了一些新的数对$(j,i)$,其中$j\lt i$。我们这里先仅考虑$a_j\geq a_i$的情况,对于$a_j\lt a_i$的情况可以类似处理。首先我们要找到最大的下标$j$,满足$j\lt i$且$a_j\geq a_i$,之后我们需要更新线段树$[0,j]$的最小值为$a_j-a_i$。之后我们要找到下一个下标$k$,满足$k\lt j$且$a_i\leq a_k\lt a_j$,同样更新线段树$[0,k]$的最小值为$a_k-a_i$。重复上面这个过程。
上面这个算法的正确性是显然的,但是时间复杂度最坏是$O(n^2\log_2n+m\log_2n)$。但是我们可以发现一个重要的性质:$a_k-a_i\lt a_j-a_k$,否则更新$[0,k]$的最小值为$a_k-a_i$是没有意义的。因此我们可以发现对于给定的下标$i$,这样的下表$j,k$最多有$\log_2M$个。因此总的时间复杂度为$O(n\log_2M\log_2n+m\log_2n)$。
题目2:给定$a_1,\ldots,a_n$,现在要求回答$m$个请求,第$i$个请求为$l_i,r_i$,要求判断$a_{l_i},a_{l_i+1},\ldots,a_{r_i}$中的数重新排序后是否能形成等差数列。其中$1\leq n\leq 10^5$,$1\leq m\leq 10^6$,且满足$l_i<r_i$,以及$0\leq a_i\leq 10^9=M$。
这个问题实际上可以转换为区间最近值问题。一个区间$[l,r]$能形成等差数列当且仅当$x-y=(r-l)d$,其中$x$为区间最大值,而$y$为区间最小值,$d$为区间最近值。剩下的就可以通过题目$1$的方式求解了。
区间最大不相交集合
题目1:给定$m$个线段,第$i$个线段覆盖$(l_i,r_i)$,包含端点。现在给定$m$个请求,第$i$个请求给定$L_i,R_i$,要求找到最大的一组线段集合,要求这些线段不能有交点,且不能越界(左边界小于$L_i$或右边界大于$R_i$)。其中$1\leq m, q\leq 5\time 10^5$
一道题目。
首先很显然如果某个线段覆盖另外一个线段,则前者和后者不可能同时出现,且前者总是可以被后者所替代,因此我们可以将前者删除。现在我们剩下的线段为互不覆盖的线段,我们不妨认为$l_1\lt l_2,\lt\ldots \lt l_n$,以及$r_1\lt r_2\lt \ldots \lt r_n$。
如果对于给定的查询区间,可选的线段实际上形成了一个区间$[L,R]$。我们可以不断的贪心加入线段来得到最优解。我们发现贪心的时候总是会选择下一条线段$i$,满足$l_i>r_j$,其中$j$是已经加入的线段的最大编号。因此我们可以从$j$向$i$加入一条有向边。
考虑现在一个请求$L_i,R_i$,我们先找到编号最小的满足条件的线段$x$,之后不断沿着有向边移动,直到遇到非法线段。这个过程可以用倍增加速,因此时间复杂度为$O((m+q)\log_2m)$。
双区间操作问题
双区间操作是指给定$n$个元素$a_1,\ldots,a_n$,记$\pi$为原序,提供一个置换$1$到$n$的置换$P$。之后要求对元素$a$进行$m$次操作,操作分两类:
- 给定$l,r$,操作$a_l,a_{l+1},\ldots,a_r$。
- 给定$l,r$,操作$a_{P_l},a_{P_{l+1}},\ldots,a_{p_r}$。
题目1:给定一个双区间操作问题。之后第一类操作是将区间中所有元素增大一个指定值$x$。第二类操作是将区间中所有元素清$0$,这里的区间是基于置换$p$下的。第三类操作是查询操作,给定$i$,查询第$a_i$的值。其中$1\leq n, m\leq 10^6$。
提供一道问题。
我们需要额外维护一个序列$b_1,\ldots,b_n$,其中$b_i$表示对$a_i$执行第二类操作的最后一个请求编号。
我们可以按照$p$的顺序重新调整$b$的顺序,这样就可以把$b$丢到线段树$B$上维护,支持对于$p$的区间修改和对于$\pi$的单点查询。
之后我们把$a$丢在另外一个线段树$A$上维护,这样就可以很好的支持第一类操作。
现在考虑第三类操作,我们需要查询某个元素$i$的值,我们可以发现此时他的值为线段树$A$上当前值减去执行第$b_i$个请求的时候的值。
因此我们可以直接离线请求后,对于所有查询预处理其$b$值,之后使用差分技术来计算。也可以借助持久化技术来实时计算。
时间复杂度为$O(m\log_2n)$。
多维区间查询问题
一维查询问题一般都很简单,可以直接上线段树,不仅支持查询还能很好地支持修改,每次操作时间复杂度为$O(\log_2n)$。
一般二维查询问题可以离线请求后用线段树来$O(n\log_2n)$时间复杂度和$O(n)$空间复杂度解决,如果强制在线可以用持久化线段树$O(n\log_2n)$时间空间复杂度解决。如果还要求支持修改,那么离线的话,可以转换成三维问题(修改发生的时间作为第三个维度的值),如果要求必须在线,则需要上树套树这种复杂的数据结构才行,时间复杂度为$O(n(\log_2n)^2)$,但是如果数据量不大的话,可以试用一下四方树,时间复杂度为$O(n\sqrt{n})$,虽然看上去复杂度还不如树套树,但是常数小还好写。
而如果问题上升到三维,对于离线问题,常数较小的方法就是使用CDQ分治,时间复杂度为$O(n(\log_2n)^2)$,其余方法都不太好(在时间复杂度这么大的情况下,常数就非常重要了,CDQ分治使用的是BIT而非线段树,因此常数特别的小)。如果强制在线可以考虑使用KD-Tree,每次查询的时间复杂度$O(n^{2/3})$。
如果维度更高,只推荐KD-Tree了,其它的方式太复杂了。
题目1:给定$n$个字符串$s_1,\ldots,s_n$,给定$q$个请求,第$q$个请求给定前缀后缀和长度范围,要求找出有多少字符串满足所有的特性。其中$1\leq n,m\leq 3\times 10^5$,且输入的字符串总长度不超过$10^6$,字符串仅包含小写字母。
这里需要注意到,如果我们把字符串丢到前缀树中维护,并计算dfs序,那么前缀和后缀实际上分别圈定了一个范围。现在我们可以认为每个字符串可以由三维向量$(a,b,c)$,其中$a$为字符串的dfs序,$b$为字符串反转后的dfs序,$c$为字符串长度。而每个请求实际上对应一个三维区间查询。
考虑到题目可以离线,结合上面提到的策略,这里的最优实现方案是使用CDQ分治。时间复杂度为$O(n(\log_2n)^2)$。
提供一道题目。
区间k小问题
题目1:给定长度为$n$的序列$a_1,\ldots,a_n$,要求回答$q$个询问:
- 给定$l,r,k$,找到$a_l,a_{l+1},\ldots,a_r$中第k小的数。
可以用持久化线段树+差分来做。时间复杂度为$O(n\log_2n)$,不过空间复杂度也是这个。
题目2:给定长度为$n$的序列$a_1,\ldots,a_n$,要求回答$q$个询问:
- 给定$l,r,k$,找到$a_l,a_{l+1},\ldots,a_r$中第k小的数。
- 给定$i,x$,将$a_i$修改为$x$
提供一道题目。
将修改看成一次删除和增加。这样我们可以借用整体二分来解决这个问题。
我们将初始值和之后的修改全部视作删除和增加操作,按发生时间排序。同理将所有查询操作按照时间排序。之后做整体二分,二分第k大值,记这个值为M。之后将修改操作分成两部分,一部分的关联值不超过M,另外一部分超过M,两部分都按照时间序排序(这个过程类似归并排序时合并的逆操作)。之后我们遍历查询操作,在考虑某个查询操作前,将所有发生时间小于它且关联值不超过M的修改操作执行掉。之后查询区间中有多少个位置不超过M,这里可以用BIT来做。
之后就和整体二分没太大区别了。但是这里需要注意的是如果一个查询失败,就是区间中元素数num少于k,这时候我们应该让k-num。之后在递归处理左右子区间的时候,一定先取消之前的所有操作。(因为这时候一些时间发生在某些查询之后的操作已经发生了)
总的时间复杂度为$O(n\log_2n\log_2(n+m))$,空间复杂度为$O(n+m)$,还是比较快的。
题目3:给定长度为$n$的序列$a_1,\ldots,a_n$,要求回答$q$个询问:
- 给定$l,r,k$,找到$a_l,a_{l+1},\ldots,a_r$中第k小的数。
- 给定$l,r,x$,将$a_l,a_{l+1},\ldots,a_r$修改为$x$
其实这和问题2没啥区别,就是修改时区间修改。我们可以将相同且相邻的元素合并为一个区间,那么初始最多有$n$个区间。考虑之后的每个操作2,最多产生两个新区间。因此总共创建和销毁的区间数都最多只有$3n$个。
之后由于是区间修改和区间查询,我们需要借助线段树。(但是其实BIT也是能做的)
总的时间复杂度为$O(n\log_2n\log_2(n+m))$,空间复杂度为$O(n+m)$。
题目4:给定一颗大小为$n$的树,每个顶点有个点权。接下来要求回答$q$个询问:
- 给定$u,v,k$,查询$u,v$唯一路径上第$k$大的点权
为每个顶点$u$建立一个权值线段树$T_u$,其中表示这个顶点到根的路径上所有顶点的点权。这里我们使用持久化技术可以$O(n\log_2n)$建立。
之后对于查询操作,我们找到$u,v$的lca,记作$l$,$l$的父亲记作$p_l$。则可以发现$T_u+T_v-T_l-T_{p_l}$表示的是路径$u,v$上的点权信息。我们可以在上面二分得到第$k$大的权值,时间复杂度为$O(log_2n)$。
总的时间复杂度为$O((n+q)\log_2n)$。
题目5:给定一颗大小为$n$的树,每个顶点有个点权。接下来要求回答$q$个询问:
- 给定$u,v,k$,查询$u,v$唯一路径上第$k$大的点权
- 给定$u,x$,将顶点$u$的权值更新为$x$。
这里我们可以把更新替换为新增和删除操作。之后可以用题目2的方式去做。
考虑整体二分,我们可以把BIT替换为LCT,就可以得到$O(n\log_2(n+q)\log_2n)$的时间复杂度。但是常数比较大。
我们也可以继续使用BIT,这时候我们维护一个序列$a_1,\ldots,a_n$,其中$a_i$表示顶点$i$到根的被标记的顶点数。那么路径上总共被标记的顶点数可以通过计算lca后再差分得到。而如何维护$a_i$呢,我们先计算出每个顶点的dfs序,之后将dfs序放到BIT上维护。每次修改单点权,只有这个顶点的子树的$a$属性需要改变,子树对应一个连续的dfs序,因此就是一个区间更新操作而已。这种方式的时间复杂度也是$O(n\log_2(n+q)\log_2n)$,但是常数会小很多。
生长问题
题目1:给定一个长着$n$株草的草坪,第$i$株草初始高度为$0$,每日生长高度$c_i$。之后给定$m$个请求,每个请求给定日期$d$和阈值$b$,农夫会收割所有草高于$b$的部分。要求对每个请求计算出收割的草的总高度。保证日期严格递增且$1\leq n,m\leq 2\times 10^5$,$1\leq c_i,d,b\leq 10^6$。
提供一道题目。
首先可以发现若草$i$的速度大于草$j$,那么每次草$j$收割的时候草$i$一定也会被收割。因此我们可以将所有草按速度从大到小排序,之后按照上一次收割时间分成若干个区间,相同区间中的草拥有公共的上一次收割时间。
之后对于每个请求,暴力枚举前面的几个区间,计算贡献。如果某个区间存在不被收割的草,则不用枚举后面的区间了。可以发现每次请求最多新建一个新的区间,每次暴力都会销毁一个区间,因此总共枚举区间数为$O(n+m)$。
我们可以使用Treap来维护每个区间,这样合并和计算总速度等都可以$O(\log_2n)$完成,总的时间复杂度为$O((n+m)\log_2n)$。
题目2:给定一个长着$n$株草的草坪,第$i$株草初始高度为$a_i$,最大高度为$b_i$,每日生长高度$c_i$。之后给定$m$个请求,每个请求给定一个区间$l,r$和日期$d$,农夫会收割编号在区间中的草,换言之,收割完成后区间中的草的高度重设为$0$,要求对每个请求计算出收割的草的总高度。保证日期严格递增且$1\leq n,m\leq 2\times 10^5$,$1\leq a_i,b_i,c_i,d\leq 10^6$。
提供一道题目。
首先我们可以把草按照上一次收割时间分成若干个区间,相同区间中的草的上一次收割时间相同,初始的时候所有草都在自己的独立区间中。
之后考虑一次请求,我们暴力枚举请求覆盖的区间,计算它们的贡献即可。之后将枚举的区间合并为一个区间。可以发现每次请求最多增加两个新的区间,而每次暴力枚举都会减少一个区间,因此总的暴力枚举区间数为$O(n+m)$。
考虑当我们枚举一个区间$L,R$时候,如何计算贡献。分下面几种情况考虑:
- 一种是区间中所有草都未经过收割:这时候区间大小一定是$1$,我们暴力计算。
- 否则区间中的草在过去某个时刻高度均为$0$,这时候我们将区间中的草按照停止生长(超过阈值)的时间排序,之后二分。这有些麻烦,我们可以使用持久化线段树,对于生长时间不超过$\delta$的统计它的总容量,否则统计它的总生长速度乘上$\delta$即可,这里$\delta$是距离上次收获的时间差。
这样总的时间复杂度为$O(n\log_2n)$,非常快。