Java编译优化
编译的生命周期
众所周知,java是半解释半编译型语言,因为一开始.java文件通过javac命令被编译成字节码.class文件,之后JVM通过解释执行的方式执行这些字节码。
这里盗大佬的一张图(可以看我参考资料中的第二个链接)
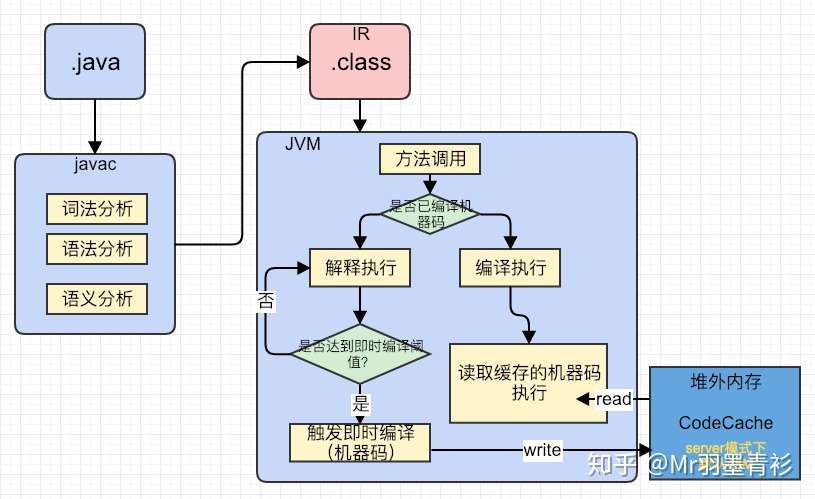
在编译原理中,编译分成前端和后端,前端负责对程序进行词法分析,语法分析以及语义分析,之后得到一个中间表示形式(Intermediate Representation,简称IR)。而这里javac是编译器的前端,而JIT则是编译器的后端,JIT将负责对字节码进一步优化并编译成机器码,从而获得媲美编译型语言的执行性能。
那么JIT这么有用,什么时候它才会编译我们的代码呢?JVM在执行我们的代码会为每个方法维护两个计数器,一个用于统计我们方法被调用的次数,另外一个统计方法中循环体被执行的次数。JIT会根据两个计数器的总和来确定一个方法是否应该被编译,如果应该,则将这个方法加入到等待队列中,这种编译形式称为标准编译,这种情况下如果编译成功,那么之后对这个方法的调用就会使用新的编译后的代码(在之前调用还未结束的方法还是使用的解释执行字节码的方式)。但是存在一种特殊的情况,比如说存在一个不会退出的方法,所有的逻辑都写在这个方法中(比如无限循环监听事件),那么我们岂不是无法享受JIT带来的优化了吗。其实不然,因为对于每个循环都有独立的分支计数器,每执行一次循环,分支计数器就会自增和自检,如果分支计数器超过本身阈值,那么循环就会获得被编译的资格,这种编译称为栈上替换(On Stack Replacement,简称OSR),一旦栈上替换完成,之后即使方法还未退出也依旧会走新的编译后的代码。
无论是标准编译还是栈上替换,都是以方法为单位进行的编译。
CodeCache
热点代码被编译成机器码后会存放在堆外的CodeCache中,可以用-XX:InitialCodeCacheSize和-XX:ReservedCodeCacheSize分别指定CodeCache的初始容量和最大容量。可以使用JDK自带的jconsole查看CodeCache的使用情况。
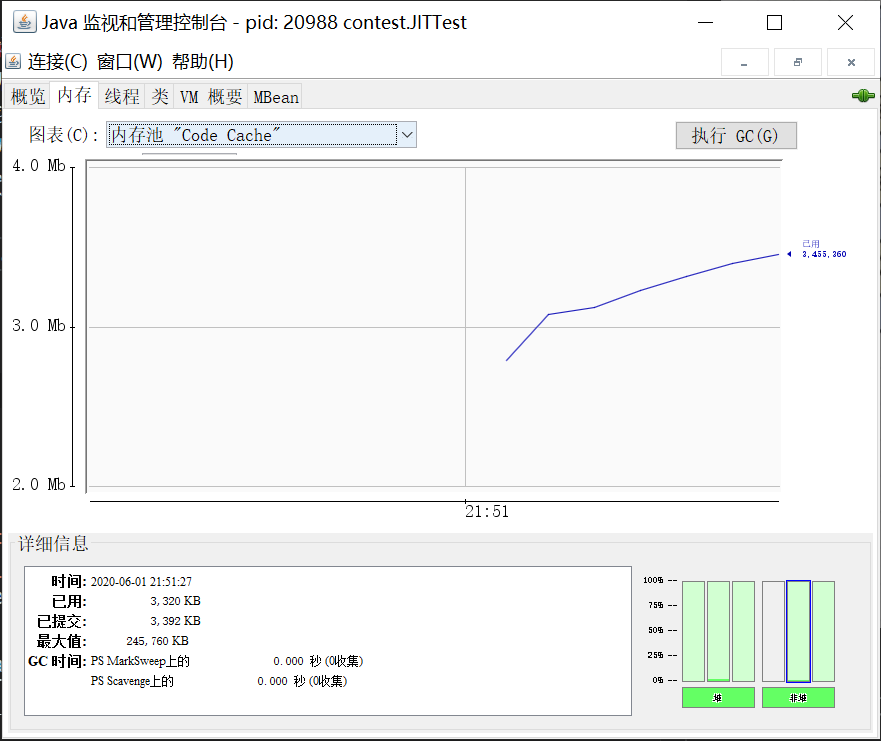
由于CodeCache是有容量上限的,一旦上限达到,那么之后的热点代码就不会继续编译了,这些代码只能以解释的方式执行。JVM可以回收CodeCache中的代码,可以用-XX:+UseCodeCacheFlushing选项开启这项功能,这个选项在JDK1.7.0_4之后是默认开启的。
分层编译
在引入分层编译之前,我们需要利用-client和-server参数告诉JVM使用编译快优化少的C1编译器还是使用编译慢优化多的C2编译器。
java7中引入了分层编译,用-XX:+TieredCompilation选项即可开启。分层编译同时拥有C1的启动快和C2的峰值性能好的特点。而在java8中,分层编译是默认开启的。而在关闭了分层编译的情况下,默认会使用C2编译器。
分层编译将代码的执行状态分成了5类:
- 解释执行
- 执行不带profiling的C1代码
- 执行仅带方法调用次数和循环被回弹次数profiling的C1代码
- 执行带所有profiling的C1代码
- 执行C2代码
这5个状态的代码的性能从大到小排列为:4,1,2,3,0。
继续盗图
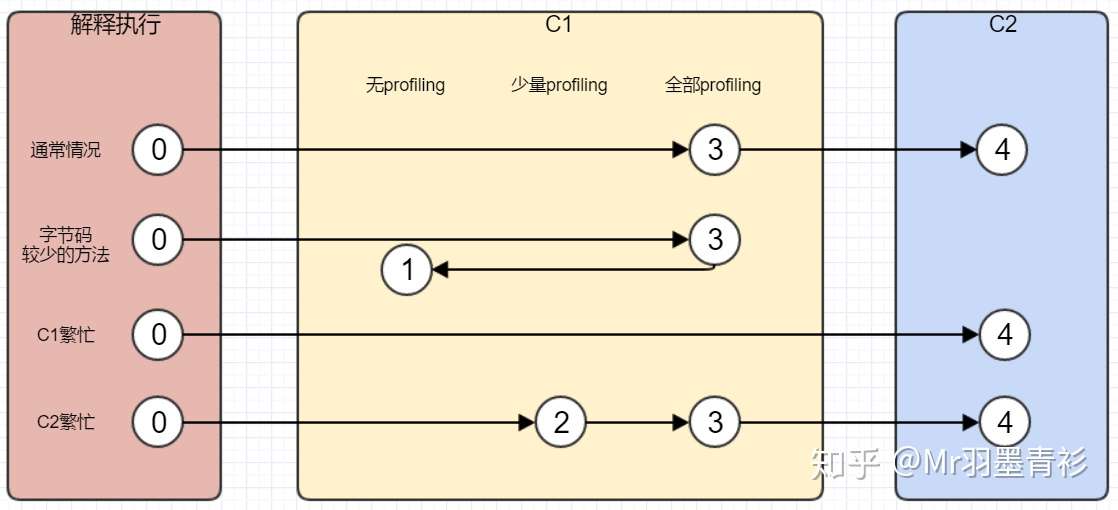
在使用-client模式的时候,JVM会启动一个编译线程,而在使用-server模式的时候,JVM会启动两个编译线程,而在使用分层编译的时候,JVM会至少启动一个C1编译线程和C2编译线程,其具体的数量与CPU核心数有关

编译线程的数量也可以通过-XX:CICompilerCount=N选项来控制,其中的三分之一线程会用于处理C1编译任务,而其余的处理C2编译任务。
编译信息
可以用-XX:+PrintCompilation这个选项要求JVM输出编译信息。
下面我们运行我们的代码:
public class JITTest {
public static void main(String[] args) {
for (; ; ) {
plus();
}
}
static int sum = 0;
public static void plus() {
for (int i = 0; i < 10; i++) {
sum++;
}
}
}
可以发现输出了大量的编译信息
106 2 n 0 java.lang.System::arraycopy (native) (static)
106 3 3 java.lang.StringBuilder::append (8 bytes)
106 5 3 java.io.WinNTFileSystem::normalize (143 bytes)
107 7 3 java.lang.Math::min (11 bytes)
108 8 3 java.lang.CharacterData::of (120 bytes)
108 9 3 java.lang.CharacterDataLatin1::getProperties (11 bytes)
108 10 2 java.lang.Object::<init> (1 bytes)
108 6 4 java.lang.String::hashCode (55 bytes)
108 1 4 java.lang.AbstractStringBuilder::ensureCapacityInternal (27 bytes)
108 4 4 java.lang.String::charAt (29 bytes)
108 11 3 sun.nio.cs.ext.DoubleByte$Encoder::encodeChar (21 bytes)
108 13 3 java.lang.String::getChars (62 bytes)
109 12 4 java.lang.String::length (6 bytes)
109 14 1 sun.instrument.TransformerManager::getSnapshotTransformerList (5 bytes)
109 15 3 java.lang.System::getSecurityManager (4 bytes)
109 16 3 java.lang.String::startsWith (72 bytes)
110 18 3 sun.nio.cs.UTF_8$Encoder::encode (359 bytes)
110 21 4 java.lang.String::equals (81 bytes)
110 22 4 java.lang.AbstractStringBuilder::append (29 bytes)
110 19 3 java.lang.String::indexOf (166 bytes)
110 24 4 java.io.WinNTFileSystem::isSlash (18 bytes)
110 23 s 4 java.lang.StringBuffer::append (13 bytes)
111 29 3 java.lang.String::indexOf (70 bytes)
111 28 3 java.util.HashMap::hash (20 bytes)
111 26 3 java.util.Arrays::copyOfRange (63 bytes)
111 30 2 contest.JITTest::plus (23 bytes)
111 17 3 java.lang.String::startsWith (7 bytes)
111 25 3 java.lang.StringBuilder::toString (17 bytes)
112 20 3 java.util.Arrays::copyOf (19 bytes)
112 27 3 java.util.HashMap::get (23 bytes)
112 32 3 java.lang.String::indexOf (7 bytes)
112 33 3 java.lang.String::substring (79 bytes)
112 34 3 java.lang.Character::toLowerCase (9 bytes)
112 35 3 java.lang.CharacterDataLatin1::toLowerCase (39 bytes)
113 36 % 3 contest.JITTest::main @ 0 (6 bytes)
113 38 n 0 sun.misc.Unsafe::getObjectVolatile (native)
113 37 3 java.util.concurrent.ConcurrentHashMap::tabAt (21 bytes)
113 39 3 contest.JITTest::main (6 bytes)
113 31 % 4 contest.JITTest::plus @ 2 (23 bytes)
113 40 % 4 contest.JITTest::main @ 0 (6 bytes)
114 36 % 3 contest.JITTest::main @ -2 (6 bytes) made not entrant
1013 41 3 java.lang.String::<init> (82 bytes)
1013 42 3 java.io.WinNTFileSystem::prefixLength (91 bytes)
1014 45 3 java.io.DataInputStream::readUTF (501 bytes)
1015 51 3 java.io.DataInputStream::readFully (63 bytes)
1015 44 3 java.io.BufferedInputStream::getBufIfOpen (21 bytes)
1015 47 s 3 java.io.BufferedInputStream::read (113 bytes)
1015 53 4 java.io.BufferedInputStream::getBufIfOpen (21 bytes)
1015 46 s 3 java.io.BufferedInputStream::read (49 bytes)
1015 44 3 java.io.BufferedInputStream::getBufIfOpen (21 bytes) made not entrant
1016 52 3 java.io.DataInputStream::readShort (40 bytes)
1016 48 3 java.io.BufferedInputStream::read1 (108 bytes)
1016 49 3 java.io.DataInputStream::readUTF (5 bytes)
1016 50 3 java.io.DataInputStream::readUnsignedShort (39 bytes)
1016 56 3 java.util.HashMap::putVal (300 bytes)
1017 54 3 java.util.HashMap::newNode (13 bytes)
1017 55 3 java.util.HashMap::put (13 bytes)
1017 57 3 java.util.HashMap$Node::<init> (26 bytes)
1017 43 1 java.io.File::getPath (5 bytes)
1019 58 4 java.lang.CharacterData::of (120 bytes)
1019 59 ! 3 java.io.BufferedReader::readLine (304 bytes)
1020 8 3 java.lang.CharacterData::of (120 bytes) made not entrant
1020 62 3 java.lang.String::toLowerCase (439 bytes)
1021 65 3 java.lang.AbstractStringBuilder::append (50 bytes)
1021 60 3 java.io.BufferedReader::readLine (6 bytes)
1021 69 4 java.lang.CharacterDataLatin1::toLowerCase (39 bytes)
1021 61 3 java.io.BufferedReader::ensureOpen (18 bytes)
1021 67 3 java.lang.StringBuilder::append (8 bytes)
1022 64 3 java.util.BitSet::get (69 bytes)
1022 35 3 java.lang.CharacterDataLatin1::toLowerCase (39 bytes) made not entrant
1022 66 1 java.net.URL::getRef (5 bytes)
1022 70 1 java.net.URL::getPath (5 bytes)
1022 68 1 java.net.URL::getQuery (5 bytes)
1022 71 1 java.net.URL::getAuthority (5 bytes)
1022 63 1 java.io.File::getPrefixLength (5 bytes)
1023 72 3 java.util.HashMap::afterNodeInsertion (1 bytes)
1023 73 3 sun.util.locale.LocaleUtils::isUpper (18 bytes)
1024 74 3 sun.instrument.InstrumentationImpl::transform (38 bytes)
1024 75 ! 3 sun.instrument.TransformerManager::transform (98 bytes)
1024 76 3 java.util.HashMap::getNode (148 bytes)
1025 79 3 java.util.LinkedHashMap$Entry::<init> (10 bytes)
1025 80 3 java.util.LinkedHashMap::linkNodeLast (33 bytes)
1025 81 3 java.util.LinkedHashMap::afterNodeInsertion (40 bytes)
1025 78 3 java.util.LinkedHashMap::newNode (23 bytes)
1025 83 3 java.lang.AbstractStringBuilder::<init> (12 bytes)
1025 77 1 java.util.LinkedHashMap::removeEldestEntry (2 bytes)
1025 82 1 java.lang.ref.Reference::get (5 bytes)
1026 84 s 3 java.util.Hashtable::get (69 bytes)
1026 85 3 java.lang.StringBuffer::<init> (6 bytes)
1026 86 s 3 java.lang.StringBuffer::toString (36 bytes)
下面是每一列的解释:
- 第一列是时间(以毫秒为单位)
- 第二列是JVM内部的编译ID
- 第三列是标识。
n表示是native方法,s表示是synchronized方法,%表示是OSR编译,!表示是否包含异常处理器,b表示是否阻塞应用线程。
可以发现plus方法从状态2变成了4,即被识别为热点代码并被C2编译器所编译,而main方法中的for循环则从状态3变成了4,即同样被C2编译器所编译并完成了栈上替换。
去优化
在使用-XX:+PrintCompilation的时候可以发现会打出made not entrant和made zombie这样的后缀。
这里需要解释一下为什么会出现made not entrant。有若干种情况;
- 第一种情况:考虑你写的某个实体类,它的某个
getter方法被频繁调用。由于我们的编译器实际上会按照现有的数据进行优化,因此虽然这个方法没有被final修饰,但是它可能会激进的猜想这个方法是不会被重载的,因此执行了内联优化。但是一旦某个覆盖了这个getter方法的子类被类加载器所加载,那么JVM会立刻意识到原先的猜想是错误的,因此原本的内联代码就被标记为made not entrant,即不允许继续调用这段代码。 - 第二种情况:这个方法可能被多次加入到编译队列中,并且在执行C1编译后,发现这段代码已经被C2编译过了,那么就会把被C1编译过的不够优化的版本标记为
made not entrant,都去使用C2编译的版本。
如果发现一段编译后的代码,在所有地方都不被调用了,就会被标记为made zombie,这样GC就可以回收这些内存。
注意made not entrant并不代表这个方法就不被调用了,可能其它的一些地方还在调用这段代码。只有made zombie后才能保证这段代码确实不被调用了。