线段树
线段树
线段树是一种非常有用的数据结构。我们可以用线段树维护一段区间$[L,R]$,从而支持在这个区间的某个子区间上进行批量操作。
其具体原理比较简单,就是树中每个结点负责管理一段子区间。比如结点x负责管理区间$[l,r]$。如果一个结点管理的区间长度大于$1$,其就有两个子结点,记作x.left和x.right,前者负责管理$[l,m]$,后者则负责管理$[m+1,r]$,其中$m=\lfloor\frac{l+r}{2}\rfloor$。
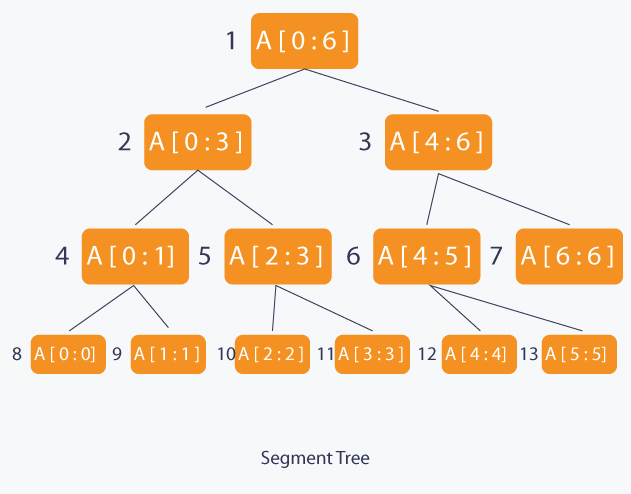
线段树的构造可以通过递归实现。
线段树合并分裂
考虑一株权值线段树,即线段树区间$[x,x]$表示的是值为x的元素数目。(如果权值过大,可以提前离散化处理)
权值线段树最大的特点就是其可以表示一个排序好的数组,我们可以快速得到第k小的元素。
现在我们希望建立多颗权值线段树,并支持合并,分裂,建树操作。
考虑建树操作,由于线段树的数目比较多,因此需要动态开点来保证内存够用。建树操作的时间复杂度和空间复杂度为$O(\log_2K)$,K是值的范围。
接下来考虑分裂操作,按照第k小元素进行分裂,我们可以递归找到第k小元素,在查找的过程中进行分裂。分裂操作的时间复杂度和空间复杂度为$O(\log_2K)$
最后考虑合并操作,将两颗权值线段树合并,我们可以暴力进行合并,只是当一株树为空时则直接返回即可。
Segment merge(Segment a, Segment b){
if(a == NIL) return b;
if(b == NIL) return a;
//递归合并线段树a、b
}
由于每次递归调用merge都意味着会销毁至少一个顶点,而总的顶点数与建树次数n和分裂次数m有关,至多为$O((n+m)\log_2K)$。
因此总的时间复杂度为$O((n+m)\log_2K)$。
提供一道题:SRM744 CoverTreePaths。
线段树上的搜索问题
问题1:给定一个区间$a_1,a_2,\ldots,a_n$,有$m$个请求,其中$n,m\geq 10^6$。请求可以分为两种:
- 给定$l,r,x$,对于$l\leq i\leq r$,将$a_i$修改为$a_i+x$。
- 给定$l,r,x$,查询所有满足$l\leq i\leq r$且$a_i\geq x$的下标$i$中最小的那个下标,如果不存在,则输出$-1$,否则输出下标
我们可以利用一个线段树维护区间,且线段树的每个顶点都维护区间最大值。
操作1可以很容易用惰性标记解决,我们考虑第二类请求。很显然我们可以二分区间进行查询,这样加上线段树的额外时间复杂度,总的时间复杂度为$O(n(\log_2n)^2)$。
上面的过程比较慢,现在我们尝试在搜索线段树的时候同时完成二分过程。这样我们要稍微修改一下线段树递归搜索的过程,我们先搜索左孩子,如果找到了,就直接返回,否则再搜索右孩子。同时在递归之前判断区间最大值是否大于等于$x$,如果不则直接返回。
很显然操作1的时间复杂度为$O(\log_2n)$,那么操作2的时间复杂度是多少呢。
考虑一次查询操作所访问的顶点,我们将其分为三类:
- 顶点所代表的区间完全落在查询区间中
- 顶点所代表的区间部分落在查询区间中
- 顶点所代表的区间与查询区间无交点
如果我们进入第一类顶点中,由于我们可以在顶点中直接端点结果是处于左孩子还是右孩子中,并且不存在回溯,因此可以保证访问的第一类顶点的数目应该是$O(\log_2n)$。
接下来考虑第二类顶点,因为区间已经给定,而线段树上最多有$O(2\log_2n)$个顶点是属于第二类,因此第二类顶点的数目为$O(2\log_2n)$。
第三类顶点只能作为第二类顶点的孩子被访问到,因此最多会有$O(2\log_2n)$个顶点被访问到。
故总共访问到的顶点数目为$O(\log_2n)$,而每次访问的时间复杂度都是$O(1)$,因此操作2每次最坏时间复杂度为$O(\log_2n)$。
这样我们就能在$O(n+m\log_2n)$时间复杂度内解决这个问题。
问题2:给定一个区间$a_1,a_2,\ldots,a_n$,有$m$个请求,其中$n,m\geq 10^6$。请求可以分为两种:
- 给定$l,r,x$,对于$l\leq i\leq r$,将$a_i$修改为$a_i+x$。
- 给定$l,r,x$,查询所有满足$l\leq j < i \leq r$且$a_i+a_j\geq x$的下标$i$中最小的那个下标,如果不存在,则输出$-1$,否则输出下标
问题2和问题1非常类似,区别在于问题2需要在线段树上维护动态规划的信息。我们可以在线段树上每个顶点中维护区间最大值以及区间中最大的两个数的和。之后查询操作就类似于问题1了,但是区别在于如果我们搜索了左子树没有找到,那么我们需要记录所有左边区间中出现过的最大值。
第二类和第三类顶点数目是固定的,无需分析。当进入到第一类顶点的时候,如果目标不在当前区间,那么我们可以直接利用顶点上维护的最大值信息更新查询状态,从而直接可以返回。而如果目标在区间中,则回继续向下搜索。因此一次查询经过的第二类顶点数最多为$O(\log_2n)$,故总的时间复杂度还是$O(n+m\log_2n)$。
Segment tree beats
问题1:要求维护一段长度为$n$的序列$a_1,\ldots,a_n$,之后有$m$个询问,满足$n,m\leq 10^6$。询问有三种类型:
- 给定$l,r,x$,对于区间$l\leq i\leq r$,将$a_i$替换为$\min(a_i,x)$。
- 给定$l,r$,查询$\max(a_l,a_{l+1},\ldots, a_r)$。
- 给定$l,r$,查询$a_l+a_{l+1}+\ldots+a_r$。
吉如一论文中的问题,并且给出了做法,这边只是简单记录一下。
我们可以用线段树维护整个序列。同时为每个线段树维护一个最大值和严格次大值,当然区间和和最大值出现次数也是不可缺少的。这里先不讲为啥一定要维护严格次大值,之后会讲到。
当操作1发生的时候,假如当前扫描的区间完全落在更新区间中,那么要分三种情况处理。
- 如果当前区间中最大值小于等于$x$,那么更新没有意义,直接返回即可。
- 如果当前区间中最大值大于$x$,但是次大值小于$x$,那么我们就打上更新标记,同时修改区间和(由于最大值出现次数也在维护,因此新的区间和是可以直接计算的)。
- 如果当前区间中次大值大于等于$x$(当次大值等于$x$时,这时候虽然我们能成功更新区间和,但是严格次大值就是非严格的了)。因此我们这时候必须暴力更新左右子区间,再利用左右子区间更新后的信息更新当前区间的信息。
这里与一般线段树的唯一区别仅为步骤3,步骤3是一个明显的暴力行为。下面我们证明上面所有操作的时间复杂度为$O((n+m)\log_2n)$。
我们这里需要借助势能分析。下面我们将线段树中存在的标记分为不同类,同一次更新操作打上的标记或同一个标记分裂后下传的两个标记是同一类,其余标记为不同类。一个线段树顶点的势能定义为以它为根的子树中存在的多少类的标记。而线段树整体的势能为线段树中所有顶点的势能之和。
很显然一次更新在不考虑暴力更新的情况下,仅仅会有$O(\log_2n)$个顶点的势能增加1,而所有标记分裂下推操作,最多会使得2个顶点的势能增加1。
下面我们考虑暴力更新操作会带来的影响,由于暴力更新发生,必定是区间中的次大值大于等于$x$,因此我们可以保证在更新操作完成后,所在顶点的势能会减少2(因为将下面最大值和次大值的标记全部回收掉),同时势能还会增加1(因为$x$的标记会打上),因此我们额外释放了多余的1点势能,这点势能的用处就是摊还掉遍历这个顶点的费用。(这就是为什么要维护严格次大值,只有这样才能同时回收两个标记,打上一个标记,总共释放一个标记)
因此我们发现所有操作的摊还后的时间复杂度都是$O(\log_2n)$,而线段树中最多包含$O(n)$个标记,每个标记对势能的贡献最多为$O(n\log_2n)$,因此这里就证明了总的时间复杂度为$O(n\log_2n+m\log_2n)$。
一道题目
问题2:要求维护一段长度为$n$的序列$a_1,\ldots,a_n$,之后有$m$个询问,满足$n,m\leq 10^5$。询问有四种类型:
- 给定$l,r,x$,对于区间$l\leq i\leq r$,将$a_i$替换为$\min(a_i,x)$。
- 给定$l,r,x$,对于区间$l\leq i\leq r$,将$a_i$替换为$a_i+x$。
- 给定$l,r$,查询$\max(a_l,a_{l+1},\ldots, a_r)$。
- 给定$l,r$,查询$a_l+a_{l+1}+\ldots+a_r$。
做法和问题1相同。下面证明时间复杂度。
首先我们需要重新定义势能。我们记线段树的势能为线段树中特殊点的数目乘上$\log_2n$,一个点是特殊点,当且仅当所有标记全部下推完后顶点的最大值和父顶点不同。
这样定义势能的好处在于摆脱了pushdown操作对时间复杂度的影响。
考虑到所有操作的非暴力部分,其只会处理$O(\log_2n)$个顶点,因此势能最多增加$O(\log_2n)$,摊还的时间复杂度为$O((\log_2n)^2)$。
接下来考虑暴力更新部分,对于每个遍历的顶点,其要么是特殊顶点,要么有个被遍历的后代是特殊顶点。考虑到暴力更新后,所有遍历过的特殊顶点都会变成非特殊的,且不会创建新的特殊顶点(暴力更新时打上第一类操作的标记不会创建新的特殊顶点)。因此暴力部分的摊还时间复杂度为$O(1)$。
因此总的时间复杂度为$O((n+m)(\log_2n)^2)$。
问题3:要求维护一段长度为$n$的序列$a_1,\ldots,a_n$,之后有$m$个询问,满足$n,m\leq 10^5$。询问有五种类型:
- 给定$l,r,x$,对于区间$l\leq i\leq r$,将$a_i$替换为$\min(a_i,x)$。
- 给定$l,r,x$,对于区间$l\leq i\leq r$,将$a_i$替换为$\max(a_i,x)$。
- 给定$l,r$,查询$\max(a_l,a_{l+1},\ldots, a_r)$。
- 给定$l,r$,查询$\min(a_l,a_{l+1},\ldots, a_r)$。
- 给定$l,r$,查询$a_l+a_{l+1}+\ldots+a_r$。
算法同问题2,时间复杂度也是相同的,分析技巧类似。
一道模板题。